


想象一下,你正在机场和朋友通电话。你周围有很多人在交谈,飞机在起飞/降落,数十个行李箱的滚轮滚过瓷砖地板,可能还有几个婴儿在哭闹。而电话那头的朋友,在一家热闹的餐厅。你的朋友需要应对自己的环境噪音:餐具和盘子叮当作响,食客们聊得起劲,餐厅播放着背景音乐,可能还有一些婴儿在哭闹。而在电话的两端,你们听到的都是平静而清晰的话语,而不是含混不清的声音。
这都得益于噪音抑制和主动降噪 (ANC)。这两项功能近来在音频产品中很常见,但它们不仅是流行词而已。这两项技术有助于以不同的重要方式减轻噪音的影响。本文将解释二者的区别,同时更深入地探讨其中的噪音抑制技术。
噪音抑制
来看看上述情景的第一部分:你在嘈杂的环境中对着麦克风讲话。
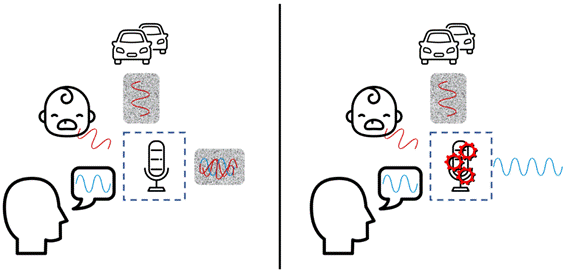
在此示例中,汽车在发出持续的背景噪音。这就是所谓的稳态噪声,它会呈现我们关注的语音信号里面并不存在的周期性特性。空调、飞机、汽车发动机和风扇的声音都是稳态噪声的例子。但是,婴儿的哭声并不是持续的,这种声音有一个很恰当的名字:非稳态噪声。这类噪声的其他示例包括哈士奇的吠叫、电钻或锤子工作的声音、敲击键盘的咔嗒声或餐厅中银制餐具碰撞的叮当声。这些噪音发生得很突然,同时存在的时间很短暂。
麦克风会捕捉这两种类型的噪音;在不做任何处理的情况下,会产生同样嘈杂的输出,盖过你期望传递的语音信息。图的左半部分显示了这种情况。但是,通过噪音抑制处理,可以消除背景噪音以便传输(而且仅传输)你的声音。
主动降噪
现在,你清晰的声音已经通过无线电传输给你的朋友,但这不代表对方就能清晰的接收你的信息。这时就需要主动降噪。
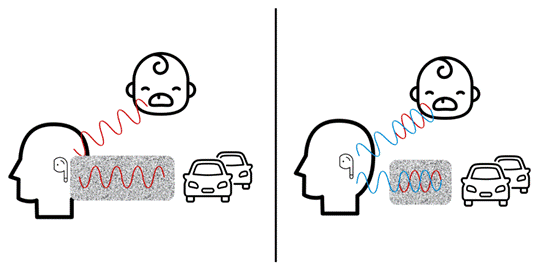
像之前一样,有稳态和非稳态噪声会影响传入耳塞的声音。与之前处理掉噪音的情况不同,主动降噪的目标是完全抵消外部噪音。麦克风捕捉传入的声音,生成外部噪音的反向信号,并通过将反向信号叠加到入耳的声波中尽可能的抵消外部噪声。概括性地说,这在概念上类似于将 +5 和 -5 这两个数字相加得到 0。
在硬件中,基于上述的这种基本原则,可以通过两种主要方式应用主动降噪。一种是前馈式 ANC,即在可听设备外使用麦克风;另一种是反馈式 ANC,即在更靠近耳朵的可听设备内使用麦克风。
前馈式 ANC 位于耳朵以外,所以对噪音更敏感。它可以在噪音传向可听设备时清晰地捕捉到噪音。然后,它可以处理该噪音并输出其相位抵消信号。这使其能够隔离特定的声音,尤其是中频声音。这包括我们在本帖前面部分提到的稳态声音,但也包括语音。但是,前馈式 ANC 位于设备外部,因此更容易受到外部噪音的影响,例如风声或耳塞在兜帽内侧不断摩擦的声音(这绝对不是经验之谈)。
反馈式 ANC 不受乱动的兜帽影响,因为它在可听设备内部,能抵抗其他各类偶然干扰。这种隔音效果很好,但成功传入耳塞的较高频声音则较难抵消。同样,内部反馈麦克风需要区分播放的音乐和噪音。而且,因为其反馈更靠近耳朵,它还需要更快地处理此信息,才能保持与前馈设置相同的延迟。
最后,还有混合主动降噪 - 你猜对了,这种方法就是结合前馈和反馈式 ANC,以功耗和硬件为代价,实现两方面的最佳效果。
深入了解噪音抑制
了解噪音抑制(抑制说话人环境噪音以便远端听话人听清)与主动降噪(抵消听话人自身的环境噪音)的基本区别后,让我们重点关注如何实现噪音抑制。
一种方法是使用多个麦克风抑制数据。从多个位置收集数据,设备会获得相似(但仍有区别)的信号。靠近说话人口部的麦克风接收到的语音信号明显比次要麦克风强。两个麦克风会接收到相近信号强度的非语音背景音。将较强语音麦克风和次要麦克风收集到的声音信息相减,剩下的大部分就是语音信息。麦克风之间的距离越大,较近和较远的麦克风之间的信号差就越大,也就越容易使用这种简单算法抑制噪音。但是,当你不说话时,或预期语音数据随时间变化时(例如当你走路或跑步,手机不断摇晃时),此方法的效果会下降。多麦克风噪音抑制当然是可靠的,但额外的硬件和处理存在缺点。
那么,如果只有一个麦克风,又会怎么样呢?如果不使用额外声源进行验证/比较,单麦克风解决方案将依赖于理解接收到的噪音特性并将其滤除。这又与此前提到的稳态和非稳态噪声定义有关。稳态噪声可以通过 DSP 算法有效滤除,非稳态噪声带来了一个挑战,但深度神经网络 (DNN) 可以帮助解决问题。
此方法需要一个用于训练网络的数据集。该数据集由不同的(稳态和非稳态)噪声以及清晰的语音组成,创造出合成的嘈杂语音模式。将该数据集作为输入馈送给 DNN,并以清晰的语音作为输出。这将创建一个神经网络模型,它会消除噪音,仅输出清晰的语音。
即使使用经训练的 DNN,仍有一些挑战和指标需要考虑。如果要以低延迟实时运行,就需要很强的处理能力或较小的 DNN。DNN 中的参数越多,其运行速度越慢。音频采样率对声音抑制有类似的影响。较高的采样率意味着 DNN 需要处理更多参数,但连带地会获得更优质的输出。为实现实时噪音抑制,窄带语音通信是理想之选。
这种处理全部都是密集型任务,云计算非常擅长完成这类任务,但这种方法会显著增加延迟。考虑到人类可以可靠地分辨大约 108 毫秒以上的延迟,云计算处理带来的延额外迟显然不是理想的结果。但是,在边缘运行 DNN 需要进行一些巧妙的调整。CEVA 始终致力于完善我们的声音和语音处理能力。这包括经过实际验证的语音清晰度和命令识别算法 - 通过这些算法,即使在边缘也能提供明确的通信和语音控制。欢迎联系我们,亲自聆听。
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||